This is my second attempt to articulate lessons learned from a recent global Azure implementation for data and analytics.My first blog post became project management centered. You can find project management tips here. While writing it, it became apparent to me that the tool stack isn't the most important thing. I'm pretty hard-core Microsoft, but in the end, success was determined by how well we coached and trained the team -- not what field we played on.
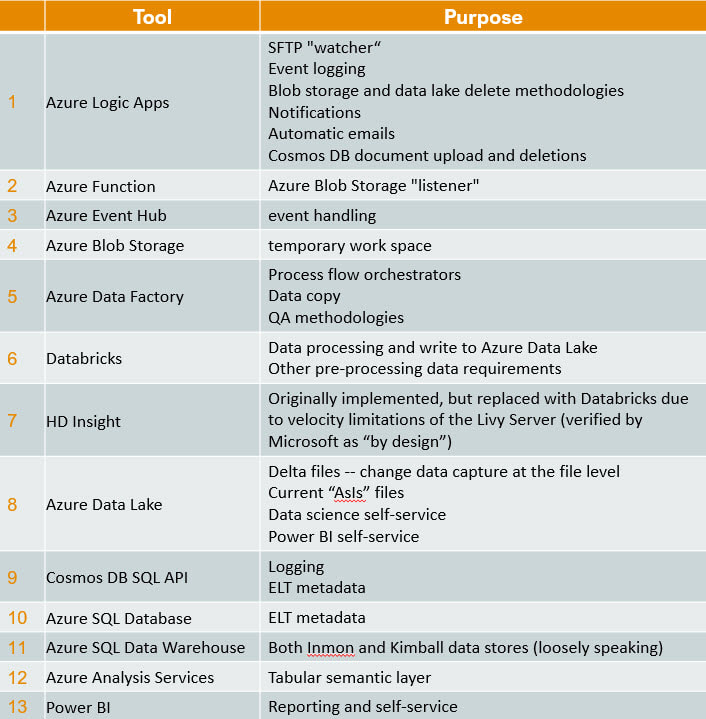
Turning my attention in this blog post to technical success points, please allow me to start off by saying that with over twenty countries dropping data into a shared Azure Data Lake, my use of "global" (above) is no exaggeration. I am truly not making this all up by compiling theories from Microsoft Docs. Second, the most frequent question people ask me is "what tools did you use?", because migrating from on-prem, Microsoft SSIS or Informatica to the cloud can feel like jumping off the high dive at the community pool for the first time. Consequently, I'm going to provide the tool stack list right out of the gate. You can find a supporting diagram for this data architecturehere.
Microsoft Azure Tool Stack for Data & Analytics Hold on, your eyes have already skipped to the list, but before you make an "every man for himself" move and bolt out of the Microsoft community pool, please read mymigration blog post. There are options! For example, I just stood up an Azure for Data & Analytics solution that has no logic apps, Azure function, event hub, blob storage, databricks, HDI, or data lake. The solution is not event-driven and takes an ELT (extract, load, and then transform) approach. It reads from sources via Azure Data Factory and writes to an Azure Database logging the ELT activities in an Azure Database as well. Now, how simple is that? Kindly, you don't have to build the Taj MaSolution to be successful. You do have tofully understandyour customer's reporting and analysis requirements, and who will be maintaining the solution on a long-term basis.
If you still wish to swan dive into the pool, here's the list!
Disclaimer: This blog post will not address Analysis Services or Power BI as these are about data delivery and my focus today is data ingestion.
Technical Critical Success Points (CSP) Every single line item above has CSPs. How long do you want to hang out with me reading? I'm with you! Consequently, here are my top three CSP areas.
Azure Data Factory (ADF)
Parameterizethe living bejeebers out of everything. Assuming an ELT methodology, haveone datasetfor every source,one datasetfor every destination, andone pipelinefor every destination. Even better, haveone linked servicefor each type (SQL Server, SFTP, Cosmos DB etc.) Reality check: this is actually impossible as not everything in ADF is parameterized, but get as close as you can get!!
Understandvolume(file size and number)vs velocity(frequency and speed) of your files. This will help you make the ADF Data Flow vs Databricks vs HDI decision.
Incorporateloggingright at the start. Log every pipeline start, success, and failure. Also log every success or failure data copy. I've gone overboard on this and logged the success or failure of every lookup and stored procedure activity. I encourage you to find your own balance.
Use ADF for your data lake data validationQAprocess. Minimally, let's assume your are verifying source-to-target row counts after every ingestion. Put this in an ADF pipeline.
Use ADF fororchestration, but don't smash everything into one pipeline --there is a40 activity limitationwhich you will quickly exceed especially with a good logging methodology. It also becomes unmanageable to troubleshot multi-process pipelines. Have a grandparent orchestrator (like a SSIS master package) which calls subject or process area orchestrators, which in turn call copy pipelines. Your DevOps team will thank you profusely!
Use a Cosmos DB document, SQL Server table or TXT file forenvironment properties. Remember environments in SSIS? It is pretty much the same idea. There should be no hard-coded URLs, blob storage or data lake locations, SQL data base names etc. in ADL parameters. Any parameter value that changes between DEV, STG, UAT and PRD should be in the environment lookup activity. There should be no global find and replace ever needed at time of deployment. I've attached a sample environment properties JSON document at the bottom of this post.
Azure Data Lake (ADL)
Plan yoursecurity methodologybefore you load your first file. Map it out in Excel or tool of choice. Data lake security cannot be an afterthought. If you skip this, there is a high probability that all your pipelines will need rework.
Don't leave a bunch of junk in your trunk! Clean up. Tomorrow never comes -- oddly, it is always tomorrow.
Assuming your data lake represents your persisted storage for reporting, useAzure Blog Storage(ABS) for temporary staging and pre-processing. This keeps your ingestion work area separate from your long-term storage. ABS is cheap and a lifecycle management policy will automatically clean up temporary work areas.
If at all possible, divide your data lake into two areas:deltas and current. For each file ingestion, deltas hold one file for adds, one file for updates and one file for deletes. This is like file-level change data capture. "Current" is what the source system looks like right now. There is no history in "current", but"current" is created by summing up all of the deltas. This allows you then toonly have one QA process on currentas there is an ingestion dependency.
Useparquet filesfor data scientists as they will know how to use them and be wanting point-in-time analysis (deltas). Provide *.CSV(current snapshot)filesfor non-technical users. Be honest with me here, have you ever known a non-technical self-service user to NOT want to open a data lake file in Excel? Point made.
Data Driven Ingestion Methodology
A data-driven ingestion methodologyderives all of its source, destination, transform, and load information from a file, table or document. (If you have worked with BIML for SSIS, this is a very similar concept.) The properties in the metadata object become ADF parameter values, are used by Databricks or HDI for file ingestion, and are used to create correct data types in SQL Server, just to name a few uses. Metadata runs the whole show. I have attached a sample file metadata JSON document at the bottom of this post.
Auto generate the metadata. Either some poor soul has to type all of this out, or a Visual Studio Python project can read each source file and spill out the metadata needed for each environment. The file metadata document I've supplied below was auto generated...along with hundreds of others. Can you even imagine creating this by hand when one source table has over a hundred columns?
If your transform and load has followed a repeatable process, you can alsoauto generate the transform views and load stored proceduresneeded by an Azure SQL Data Warehouse (ADW) where CTAS() is your bff (best friend forever). This will require an extremely accurate source-to-target mapping document. I would consider the auto-gen process successful if it correctly turns out 90% of what is needed for an ADW load.
Wrapping It Up Supporting Applications It is only honest to share three supporting applications that help to make all of this possible.
Linkto creating a Python project in Visual Studio. Linkto Azure SQL Data Warehouse Data Tools (Schema Compare) preview information. At the writing of this post, it still has to be requested from Microsoft and direct feedback to Microsoft is expected. Linkto integrate Azure Data Factory with GitHub. Linkto integrate Databricks with GitHub.
Sample Files Below are example of data driven metadata and environment properties. Both are in JSON format.






-1.png)


Leave a comment