
Describe Cloud Concepts: AZ-900 Azure Fundamentals Certification Exam Preparation
Need help? Talk to an expert: ![]() (904) 638-5743
(904) 638-5743



Have you heard about Azure Data Explorer? In this post I’d like to tell you about this cool and powerful technology that was released in February in the Azure Platform as a Service space.
Let me begin with Microsoft’s definition. Data Explorer is a fast, highly scalable data exploration service for log and telemetry data. It helps to handle the many streams emitted by modern software to help you store and analyze data. It’s ideal for large volumes of diverse data from any data source like websites, applications and IoT devices. Then this data can be used for diagnostics, monitoring, machine learning, as well as other analytics capability, and then perform complex ad hoc queries on the data in seconds.
To simplify, Data Explorer is a cloud service that ingests structured, semi structured and unstructured data, then stores this data and answers analytics ad hoc queries on it with very low latency and again, making it easy to perform complex ad hoc queries quickly.
How quickly? Data Explorer has speeds of up to 200 megabytes per second, per node and you can scale that out to 1000 nodes, thus queries across billing records take less than a second and scale up to terabytes in minutes. This allows you to ingest large volumes of data, perform preliminary analysis then integrate these incoming datasets with existing datasets.
Where and how is Data Explorer used? We’re able to use multiple heterogeneous data sources of structured and unstructured formats. In the diagram below you’ll see there are lines of business or point of sales, CRM, graphical images, social media, IoT and cloud data. From there you ingest the data, including real-time streaming data sources (the image showing the Azure Hub Services).
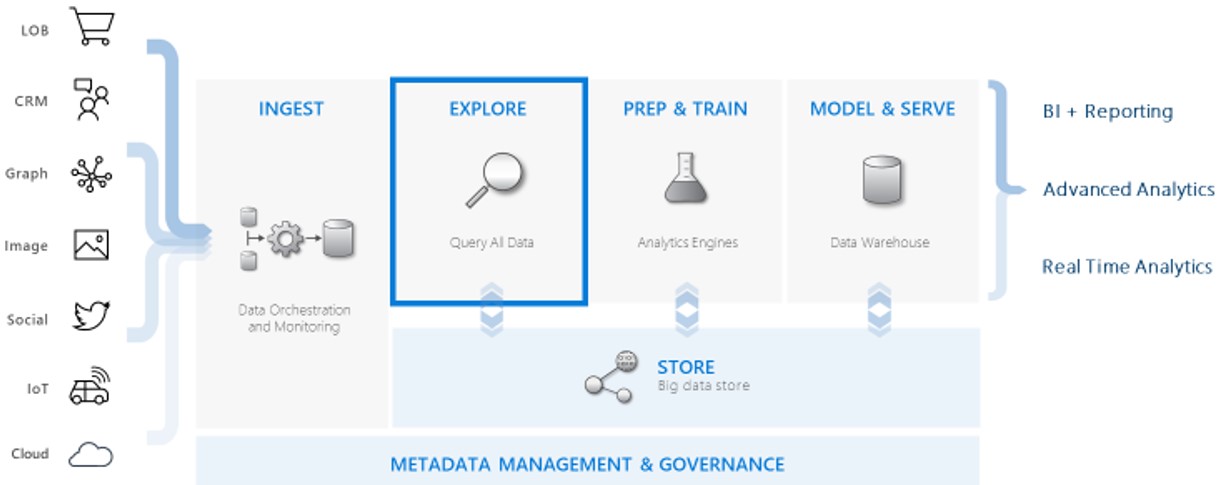
Azure Data Explorer’s superpower is with exploring the data. You’re able the query and profile the incoming data so you can make sense of the data, profile it so you can adjust downstream and manipulate how you need it. It uses Kusto query language, which is a fairly new, structured language that you can pick up quickly.
The next step is to prep and train. This is where you’d use Azure Databricks to overlay some machine language and artificial intelligence to make sense of and structure your data then continue to your endpoints. You could put it in a conventional structure such as a data warehouse or a data lake for your big data analytics engineering approaches and then perform real time analysis or whatever you choose.
Visualization can be done by Azure Analysis Services in Power BI or Cosmos DB and apps for real time analysis. Also noteworthy is that there is master data management involved as a foundation piece underneath that.
The image below shows the factory pattern for using the Data Explorer; the 3 steps here being: create a database, then ingest it and lastly, query it.
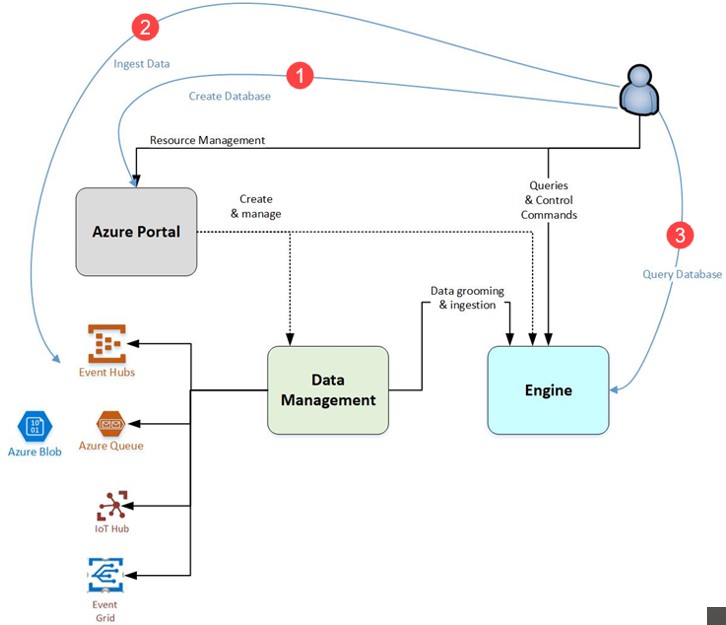
Visualization can be done by Azure Analysis Services in Power BI or Cosmos DB and apps for real time analysis. Also noteworthy is that there is master data management involved as a foundation piece underneath that.
This next image shows the greater context of how this all fits together:
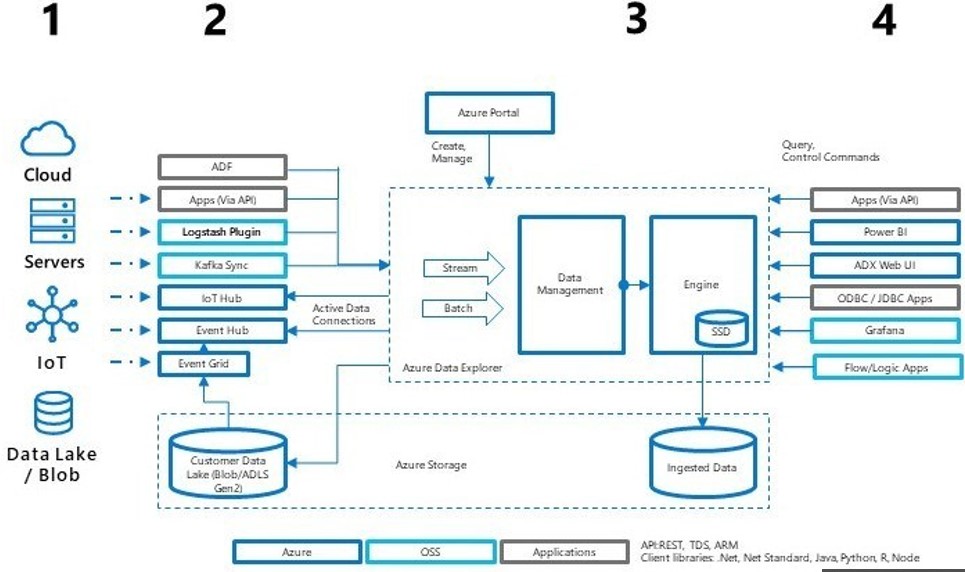
So, that’s a dive into the capabilities of Azure Data Explorer. To learn more about implementation, visit the Microsoft site to read up on the product documentation or contact us. We can help you to learn or integrate any Azure product or service with our team of experts. Click the link below or contact us – we’re here to help you take your business from good to great.



-1.png)


Leave a comment